












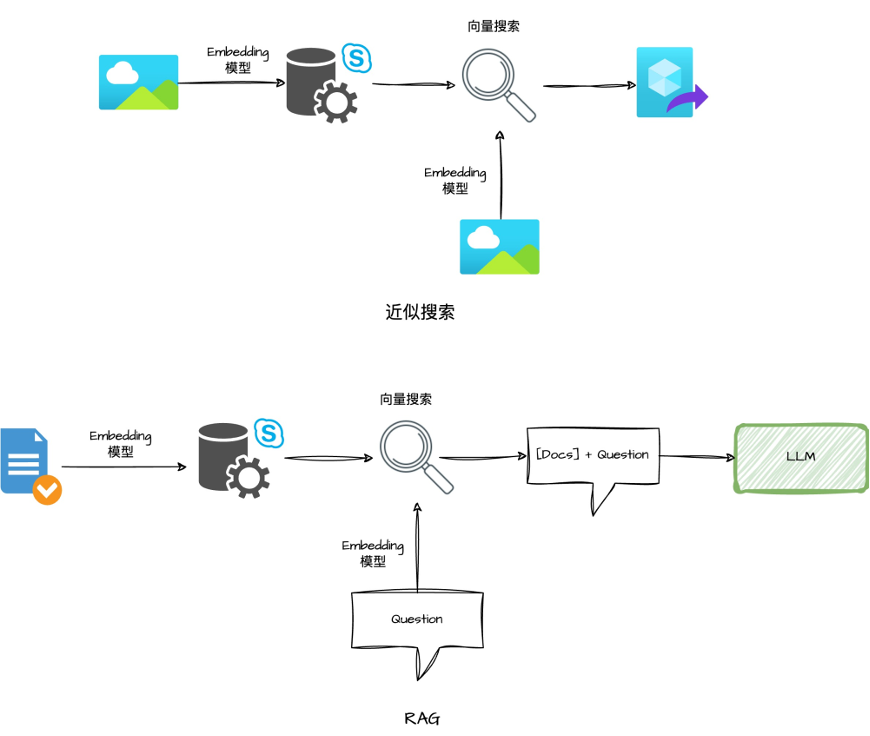
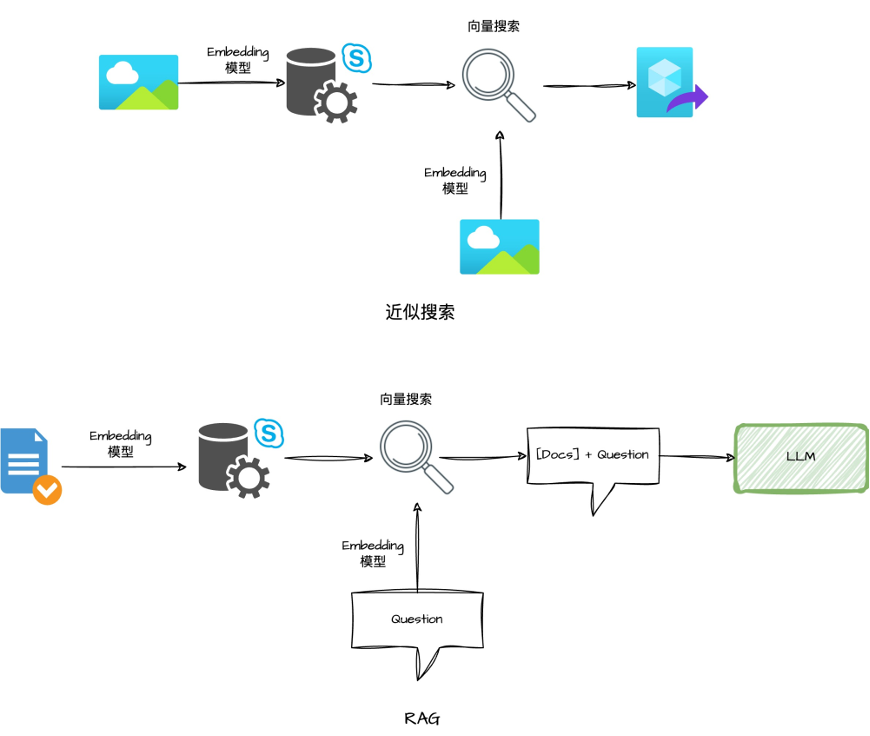
把文字变成"数字坐标" :系统使用一种叫"Embedding"的AI模型,将每段文字转换为一个高维向量——可以理解为一个"语义坐标"。"注塑成型"和"注射成型"的意思相近,所以它们的"坐标"也很接近;而"注塑成型"和"结构力学"意思不同,坐标就离得远。 建立高效索引:当文档量很大时,系统需要建立索引来快速检索。目前最流行的算法叫HNSW(分层可导航小世界图),就像给图书馆建立了分层导航系统——你想找某一类书,先定位到楼层,再定位到区域,最后精确到书架。 计算"距离"找相似:当你输入查询时,系统把你的问题也变成"坐标",然后找出"距离最近"(语义最相似)的文档返回给你。
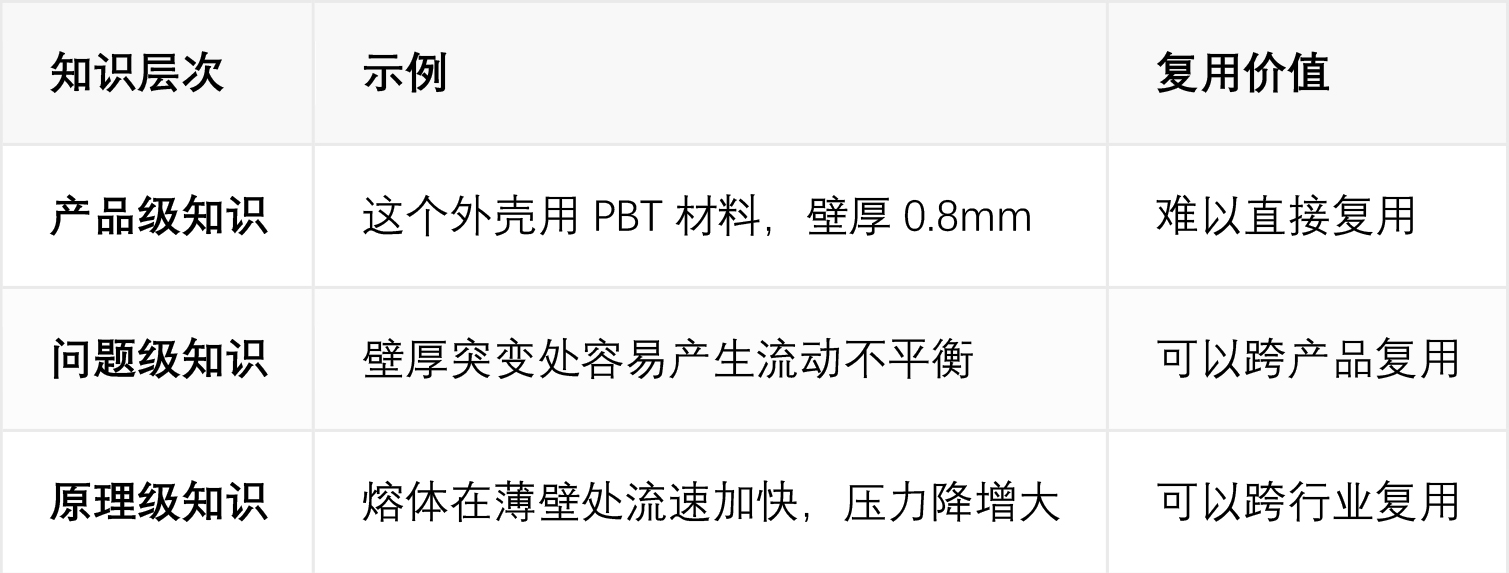
数据海量且复杂:一次完整的模流仿真,可能产生几十个参数、数百张分析图表、数万行数值结果。工程师需要的不是原始数据,而是"当时怎么分析这个问题"的决策逻辑。向量搜索能提炼出这些隐性的工程知识。 知识高度依赖经验 :仿真结果的优劣,很大程度上取决于工程师的"感觉"和"经验"。比如看到某个压力分布图,资深工程师能立刻判断出哪里可能出问题。这种经验很难标准化,但向量搜索能让它被检索和复用! 共性问题高度互通:"壁厚不均匀导致的翘曲"、"浇口位置不当导致的短射"、"纤维取向导致的力学性能差异"——这些问题在不同产品、不同材料中反复出现。向量搜索能跨越项目边界,把相似问题的解决经验关联起来。
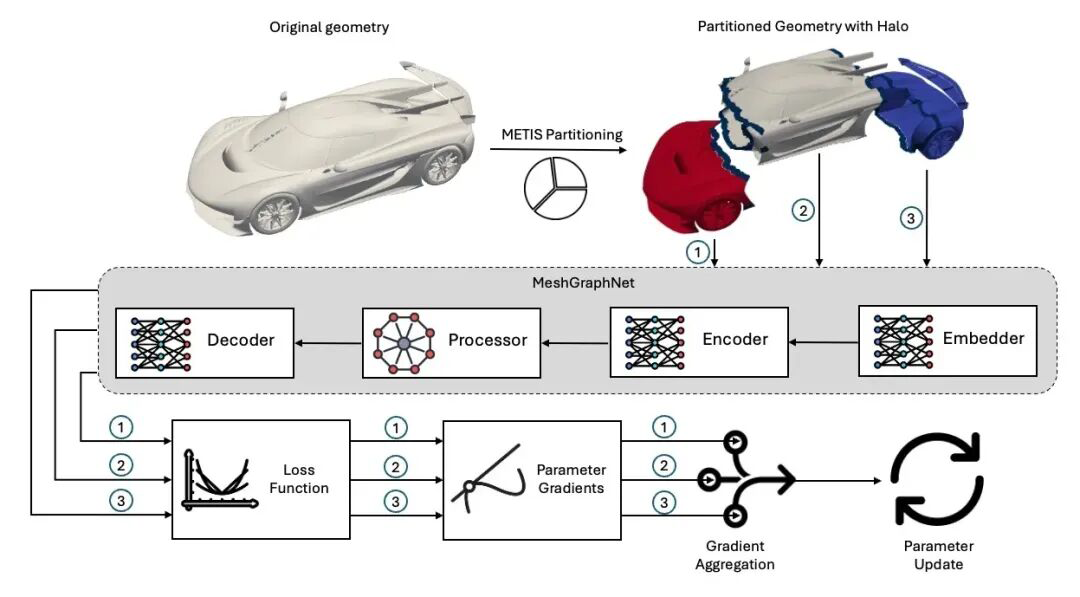
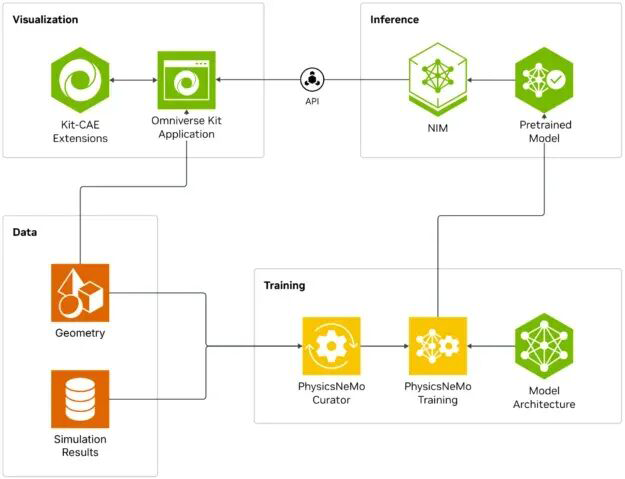
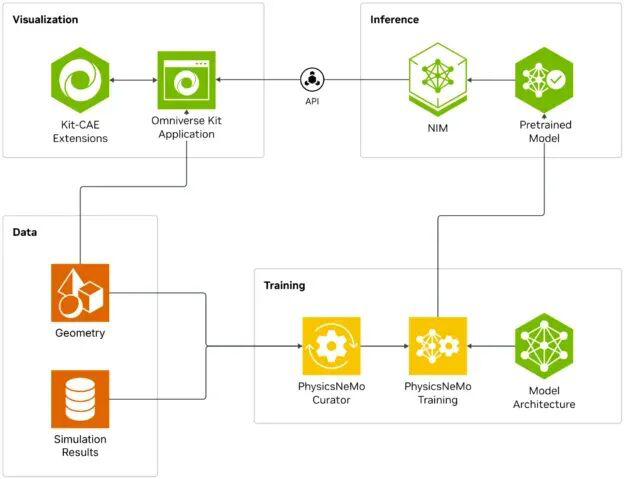
加速倍数:将设计过程加速10-100倍 应用场景:支持结构、流体、电磁等多种物理场 技术特点:基于历史仿真数据训练AI预测模型
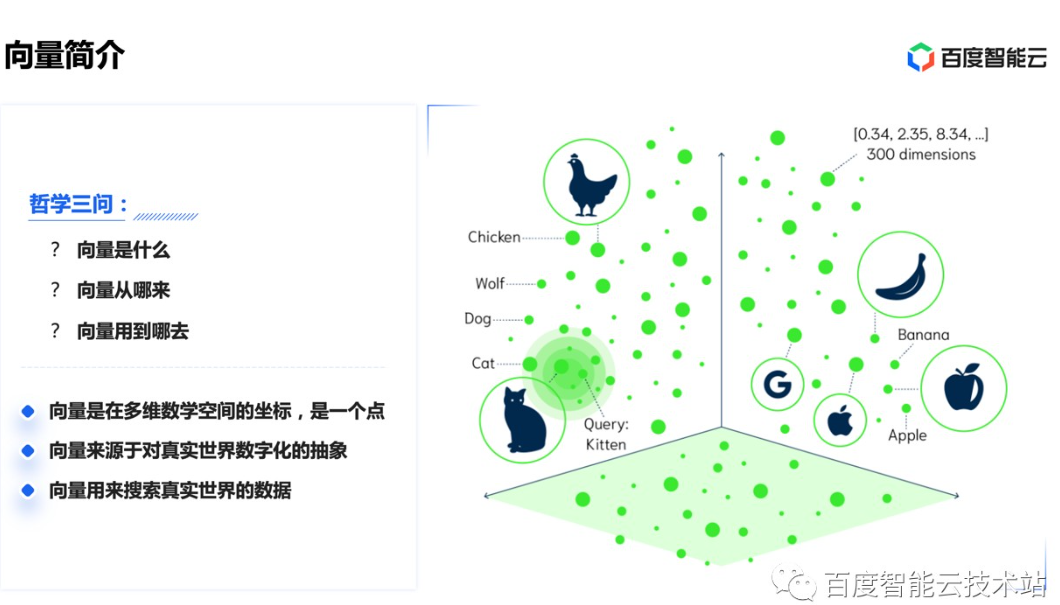
智能工程知识问答系统示意图
你检索"浇口尺寸设置",系统返回了10个结果,相似度分数都在0.75-0.78之间 实际上,第3个结果才是真正相关的,但被淹没在"还行"的结果里 更可怕的是:无论你输入什么查询,返回的结果都差不多!
当使用非常复杂的Embedding模型(如1536维的OpenAI模型)时 当数据量超过100万条且向量维度超过512维时 当文档内容非常多样化时
使用合适的降维技术(如PCA) 选择维度适中的Embedding模型(如256-512维) 使用针对工程领域微调的Embedding模型——这是最关键的一点!
检索质量问题:检索到的文档与用户意图不匹配 语义边界模糊:某些工程概念在Embedding空间中的区分不够清晰 训练数据偏差:通用Embedding模型对专业工程术语的理解不准确
使用针对工程领域微调的Embedding模型——通用模型(如OpenAI text-embedding-3-large)对你的专业领域理解有限 在检索后增加人工审核环节 使用RAG架构时,明确标注知识来源供用户验证 定期评估输出质量
建立知识质量评分机制(按时间、材料类型等维度) 定期更新知识库,标注"已过时"内容 区分"通用工程原则"和"特定产品经验"
历史仿真报告只写"参数设置见附件",附件在哪?找不到 技术总结只有结论,没有当时的分析过程 参数设置的理由只写了两个字:"试的"
建立文档规范,鼓励工程师记录关键决策 从最有价值的文档开始,逐步扩大覆盖面 设定最低文档质量标准——低于标准的文档不上线
目标设定过高,一次性要做"完美的知识库" 缺乏持续运营机制,上线即停滞 工程师觉得"不如我自己记得清楚",不愿使用
初始参数可以直接借鉴成熟方案 第一轮仿真结果与预期的偏差更小 调试轮次从平均8-10次降至4-5次(保守估计)
企业知识复用率从10%提升至50%以上(需要持续补充数据) 新人培养周期从6个月缩短至2-3个月 重复"踩坑"的情况显著减少
基础版:10-30万元 完整版:30-80万元

盘点现有的仿真知识资产(历史报告、参数文档、技术总结、会议纪要等) 建立知识分类体系:按产品类型、材料类型、工艺类型、问题类型等维度组织 评估数据质量,识别缺失严重或过时的领域 确定优先级——哪些领域的知识复用需求最迫切?
该领域的历史项目数量(越多,参考价值越大) 参数设置的复杂度(越复杂,历史参考价值越高) 工程师反馈的"找资料难"程度 知识流失风险(是否有资深工程师即将离职?)
收集用户反馈,持续优化检索结果 定期补充新项目数据,扩大知识库覆盖面 补充知识来源(邮件、微信记录、技术博客等非结构化内容) 探索与LLM的深度集成,实现更智能的问答 建立知识质量评估和更新机制
第一阶段结束时:完成知识资产盘点报告 第二阶段结束时:系统上线并完成内部测试 第三阶段(运营6个月后):检索满意度>80%,知识复用率提升30%
从知识库检索与问题相关的文档 将检索结果作为上下文加入提示词 由大语言模型基于上下文生成回答
工程师使用智能系统进行仿真的未来场景
相关文章:
技术分享|了解塑料的“流动密码”:Cross-WLF粘度模型